In this post, I make a case for a new DID method that is an evolution of the current version of Sidetree, herein referred to as Sidetree V1. I believe Sidetree V1 is the best DID method we have today: it's fully permisionless, sufficiently decentralized, cost-effective, supports multiple storage media, and can scale to billions of DIDs; however, it's not good enough—not offering consistent guarantees for functionality across chains, being overly complex and inefficient in some areas, and not supporting game-changing features like human-memorable names. Sidetree V2, or did:x, will be a new method that aims to be the default choice for anyone creating a new DID. I don't have a full design yet, but after discussing with a group at IIW 35, and colleagues at TBD and DIF, I have enough ideas to start, and with your help, finish.
Decentralized Identifiers
I will assume most of my readers are oriented to the DID space, so this background section is optional. You can expand the section below if you're new or need a refresher.
Intro to DIDs
Decentralized Identifiers (DIDs) are a new type of identifier for digital entities (individual or organization) that aim to provide a way to create and manage self-sovereign digital identities. Any entity can prove and exert complete control over its identifier and associated data, creating a concept for digital identity. A DID is a globally unique identifier not inherently dependent on any centralized authority or service for its creation, management, or resolution.
In contrast to traditional identifiers such as email addresses or usernames, often managed by centralized services or authorities, DIDs are designed to be fully decentralized, giving individuals and organizations greater control over their identities and personal data. Notably, there is no requirement that DIDs are decentralized. Many DID methods are centralized! This is a powerful aspect of decentralization in the market: choosing what centralization or decentralization story makes the most sense for your use cases.
DIDs resolve to DID Documents, which contain public key material and service endpoints — URIs pointing to other resources you wish to associate with your identifier. By design, DIDs are extensible and allow endless customizability for whichever use cases you can imagine.
Importantly, not only are DIDs a technology, but they are also a philosophy that brings its users into the decentralized web. With DIDs, the decentralized web becomes DID-relative. DIDs can underpin all decentralized interactions, meaningfully increasing user control, security, privacy, and decentralization on the internet.
Shortcomings of DIDs
Before we dive into what DID methods we have today and why I don't believe they're sufficient, let's talk about DIDs as a class.
DIDs aren't perfect. In fact, they're quite contentious. So contentious that there were formal objections by large tech companies (Google, Apple, Mozilla), resulting in a multi-year fight that ended in the director of the W3C, Tim Berners Lee, needing to weigh in and allow DIDs to become a W3C Recommendation.
DIDs have yet to see mainstream adoption despite billions of dollars flowing into the blockchain space. It's true that the U.S. DHS is working to support DIDs, along with the governments of BC in Canada, New Zealand with their COVID passes, and the EU with their EBSI project, not to mention corporate entities like Microsoft with their Entra product, Okta, Mastercard, IBM, and many others; however, I've yet to feel the simple consumer-focused success in the DID space of a project like ENS, y.at, or Unstoppable Domains.
Are DIDs relegated to be the unsexy corporate/government blockchainish play in the decentralized world? I don't think so, and we should not accept that as our fate. Here are the two main problems I believe DIDs, independent of any DID method, need to overcome to change this reality:
1. Human-Friendly Identifiers
Nobody is going to remember did:key:z6MkhaXgBZDvotDkL5257faiztiGiC2QtKLGpbnnEGta2doK, or did:ion:EiClkZMDxPKqC9c-umQfTkR8vvZ9JPhl_xLDI9Nfk38w5w, or did:keri:EXq5YqaL6L48pf0fu7IUhL0JRaU2_RxFP0AL43wYn148. They might remember did:web:example.com, but it's because it's a domain name—not decentralized.
Human-friendly identifiers are important. Names are everywhere. We have email addresses, Twitter handles, phone numbers, and countless other identifiers that we memorize, share with others and use to associate facets of our digital selves. Every user, every account, and every instance of you in a digital form has a name. Certainly, not all of these names need to be human-friendly. But if we're talking about establishing the digital versions of ourselves in a decentralized manner, having a human-friendly identifier is vitally important!
For the same reasons we choose decentralized tech, we need decentralized names. We should not have to risk centralization and censorship with the identifiers we represent ourselves within our digital world. It is not easy to come up with a human-friendly naming scheme that's truly decentralized. All solutions I've encountered have some centralizing aspect: ENS is tied to Ethereum, Unstoppable Domains are tied to Polygon, which, as far as I can tell, is an Ethereum with worse decentralization guarantees, and so on.
The more seamless your identification, the more seamless your discovery, engagements, and interactions. If we can design a more decentralized human-friendly naming system, we'll have unlocked the next million, if not the next billion, users of DIDs.
2. Meaningful Interoperability
Blockchains like Ethereum see a lot of action, partly because they provide interoperability out of the box. Ethereum decides a lot of things for you: how you write code, how you define accounts, what key types and cryptographic operations you can use, how you send messages, and how you pay for things, in addition to "solving" your story about decentralization, security, etc. By being blockchain independent and capable of being independent of blockchains, you lose all of that and must come up with it on your own.
Forcing functions are important, and the DID ecosystem has no past government or corporate mandates. Not quite the open, decentralized world we had hoped for. This was a major critique of the DID-core spec, and I believe it holds today. Interoperability can be defined in several ways: full compatibility, similar feature sets, and so on. DIDs are interoperable in a fairly weak form of the word: they follow roughly the same data model and mostly rely on the same concepts.
Without a forcing function in the DID space, enabling the level of interoperability that a blockchain like Ethereum providers, DIDs are relegated to be mechanisms for divergence. Fortunately, Decentralized Web Nodes (DWNs), a specification being pushed forward by my team at TBD via the DIF, aim to be just the interoperability glue that the ecosystem has lacked for so many years. If DWNs are to be successful, we will have a DID-routable internet where DID resolution, DID resources, and DID relativity are the norm. Lowering the barrier to interoperability should be the #1 goal for DID:X.
Which DID Methods do we have today?
Some say that every time you look at the number of DID methods registered, it grows by 15. Methods are continually being proposed and developed by different organizations and communities. As of February 2023, over 160 DID methods are registered with the DID Specification Registry.
Each DID method has its unique method-specific identifier scheme, which defines the format of the DID and how it is resolved, updated, and used. Each method has unique features, advantages, and limitations. It's up to individual users and organizations to choose the best method that suits their needs and requirements.
did:<method-identifier>:<did:suffix>At a glance, it seems that there's a healthy mix of backing stores for DID methods: public (did:btcr) and permissioned (did:indy) blockchains, off-chain methods (did:key), and storage-agnostic methods like Sidetree or did:keri. Unfortunately, it's hard to tell which DID methods are actively maintained and have real-world usage. Quite a few are fairly niche. Some are certainly abandoned. Others you would never want to use at all.
What Makes a Good DID Method?
Many DID methods can be "good" for specific use cases. Let's define a few criteria by which we'll judge DID methods. We're aiming high. Our ideal DID method must:
- Be ledger agnostic to reach the widest possible audience (users, businesses, developers). This means a common feature set shared by all method implementors, promoting interoperability.
- Support robust security features such as key rotation, recovery, deactivation, multiple key types, and advanced operations such as multisig.
- Be sufficiently decentralized, whereas sufficient decentralization is defined as having the following properties:
a. Trustlessness: not needing to trust any other participant in the system; able to fully validate all state yourself.
b. Censorship resistance: no one party, or collection of parties, can successfully censor information on the network.
c. Low cost: An average user should be able to host and run their own infrastructure, promoting network decentralization and reducing reliance on centralized providers. - Be able to scale to billions of DIDs while maintaining sufficient decentralization.
Existing DID Options
Several existing DID methods purport to fit this criterion. First, I've narrowed down methods to the list of Ledger Agnostic methods, of which there are currently eight options, Sidetree not included. I've eliminated the methods bee, jwk, self, sideos, and onion, which either do not support the above features or appear to have been abandoned. This leaves us with three methods: orb, keri, and oyd. Expand the section below if you're interested in my reasoning. You can probably guess my conclusions.
DID:ORB
Orb is an extension of the Sidetree V1 protocol that does not rely on a blockchain.
As the specification states...
The decentralized network consists of Orb servers that write, monitor, witness, and propagate batches of DID operations. The batches form a graph that is propagated and replicated between the servers as content-addressable objects. These content-addressable objects can be located via both domain and distributed hash table (DHT) mechanisms. Each Orb witness server observes a subset of batches in the graph and includes them in their ledgers (as append-only Merkle Tree logs). The servers coordinate by propagating batches of DID operations and by monitoring the applicable witness servers' ledgers. The Orb servers form a decentralized network without reliance on a common blockchain for coordination.
It seems Orb has invented a permissioned blockchain without calling it a blockchain: a system of servers that coordinate and propagate data of a known shape, forming a decentralized network for resvolability and verifiability of data. Or maybe a kinder interpretation is that Orb has cut the blockchain layer of Sidetree and added Certificate Transparency concepts in its place.
Federation and witness logs are what I like to think of as "good enough" decentralization. In the sense that those that use such a system view the level of decentralization they're aiming for as "good enough." They may be right! Orb is an interesting design and demonstrates a strength of Sidetree: the ability to choose a sufficient level of decentralization while maintaining a base level of compatibility with other Sidetree DIDs. I'd like to highlight Orb's solution to Late Publishing, which is worth a read. We'll come back to that. That said, a truly decentralized design likely has distinct considerations from a federated design; however, whether federation is a means of sufficient decentralization is a discussion for another time.
DID:KERI
KERI stands for Key Event Receipt Infrastructure. It defines itself as...
a system for secure self-certifying Identifiers which aims at minimum sufficiency and maximum security. It defines mechanisms for proving the Root of Trust for self-certifying Identifiers and their associated Key State. This spec defines a transform from Key State to DID Document, such that any valid Key Event Log can be processed into a DID Document.
KERI is ledger-agnostic and does not require a ledger whatsoever. It's self-certifying with its Key Event Logs. I won't pretend to understand KERI fully, despite my effort. I'd even go as far as to bet fewer than five people on the planet truly do. The KERI whitepaper is 140 pages long, and this doesn't include the ten current KIDs which expand on the protocol, many of which are novels in their own right. KERI is, in fact, so confusing their docs even address the question. If you are one of those five people, please get in touch with me and help me understand the system better.
KERI may check all the boxes I've listed above, but it fails the x-factor test. A system so complex is bound to fail in complex ways. The more approachable a design, the more eyes and crucial critique it can receive, improving the system. I'm not interested until a much simpler KERI comes out.
DID:OYD
At first glance, OYD seems similar to Orb if the Sidetree requirement had been dropped. OYD also seems similar to KERI, utilizing a self-certifying state log for a DIDs history.
The specification states...
OYDID takes the approach to not maintain DID and DID Document on a public ledger but on one or more local storages (that might be publicly available). Through cryptographically linking the DID Identifier to the DID Document, and furthermore linking the DID Document to a chained provenance trail the same security and validation properties as a traditional DID can be maintained while avoiding highly redundant storage and also works in settings without general public access.
By not requiring a public ledger or any storage system with strong guarantees for availability, resilience, or redundancy, it appears OYD is a weaker version of the previously explored options.
As a bonus, let's talk about the widely used, and successful method, did:web. DID Web isn't ledger agnostic since there's no ledger involved. Though, many have argued that it is decentralized, and leverages the existing trust models on the internet today, which may reach better levels of decentralization than ledger-based methods.
What decentralization means and how to evaluate decentralization are questions that are too large in scope to cover in this post. As a shorthand, we can rely on the principles set out in the what makes a good DID method section above.
DID:WEB
Though did:web is not ledger agnostic; it is provider agnostic. This means you can have your own DID if you can access a web server. This is a decentralizing factor, as anyone can host or rent their web server, buy their own domains, get their own TLS certificates, etc. Of course, you're relying on centralized providers to get a domain, TLS certificate, or any other infrastructure along the way.
did:web is low cost and scales to billions—there are already billions of websites. It's accessible to all users of the web today. Tooling can always be improved, but the barrier to getting started with a did:web DID is lower than most other DID methods out there that require some technical know-how. did:web DIDs have a relatively solid feature set, as defined by the spec. Whatever your implementation can handle, did:web can support. If you want to create a multi-sig did:web method, you can do it.
The biggest factors to overcome when considering did:web are how it can be censored: through domain registrars, DNS resolvers, web hosts, Certificate Authorities, and likely others. It's worth noting that similar censorship risks exist for other most other DID methods. No matter where you are on today's web, there are centralizing aspects.
Now that we better understand why existing DID methods aren't fit for purpose, we're back to Sidetree. Sidetree fits our criteria but has room to improve. Let's explore where Sidetree is today and where to take it next.
Sidetree
From the DIF spec...
Sidetree is a protocol for creating scalable Decentralized Identifier networks that can run atop any existing decentralized anchoring system (e.g. Bitcoin, Ethereum, distributed ledgers, witness-based approaches) and be as open, public, and permissionless as the underlying anchoring systems they utilize. The protocol allows users to create globally unique, user-controlled identifiers and manage their associated PKI metadata, all without the need for centralized authorities or trusted third parties.
Sidetree aims to scale to billions of DIDs while maintaining the properties necessary for security and decentralization. Sidetree is not a DID method but a protocol that allows DID methods to be created following its methodology. DID methods using Sidetree include ION (Bitcoin), Element (Ethereum), Photon (Amazon QLDB), and, as mentioned above, Orb (Certificate Transparency), and probably some others. All Sidetree DID methods support a common set of DID operations: create, update, recover, and deactivate. Each operation requires a key rotation, and each DID has a separate recovery key for safety.
Sidetree is a Layer 2 system that sits on top of a ledger or other storage mechanism used for anchoring. The three main components of the architecture are (from the bottom up) the anchoring system, the Sidetree nodes themselves, and Content Addressable Storage, or CAS. This modular design allows flexibility of implementations and the ability to scale out purpose-fit components for each part of the stack. For example, IPFS is a common CAS choice used across Sidetree implementations, while the anchoring systems are more diverse (different blockchains, databases, etc.). Sidetree nodes make up the system's heart, responsible for surfacing the Sidetree API, processing transactions, and communicating with both the CAS and anchor services. In the ideal, the Sidetree node can be used with multiple CAS and anchor services, though this depends on the implementation.

Some complexity comes into Sidetree when examining how operations are composed and stored. A series of files, some prunable, are used to reconstitute the state of any DID stored on the network. The spec goes into significantly more detail here.

One neat feature of Sidetree is the distinction between long and short-form DIDs. Short-form DIDs are what you're most familiar with. Long-form DIDs are, as the name implies, longer DIDs, which have the DID state appended to the end of the identifier. This allows you to have a self-certifying DID in the style of KERI and OYD without relying on a Sidetree node or any other network-connected service.
Sidetree has been meticulously designed. It has a ton of features, too many to go into here. If you're up for it, I'd suggest reading up on Value Locking, Guidelines, CAS File Propagation, Commitment Schemes and their usages, and Protocol Versioning, among other highly-detailed and well-reasoned sections of the spec.
By all means, Sidetree is quite an accomplishment. It checks most of the boxes for the requirements we outlined earlier. It has many implementations, has faced a significant peer review, and has been battle-tested in production environments by multiple companies since its official publication in March 2021. But, it has some clear room for improvement.
An Elephant
Before introducing DID:X we need to address the elephant in the room. Wouldn't it be hypocritical of me to criticise how many DID methods there are at the same time as proposing a new one?

Yes, creating a new competing standard is problematic. My view is that introducing new divergent standards is more problematic. As I mentioned above, meaningful interoperability is a problem that all DID methods face. If a DID:X can be a contender for the end-all-be-all DID method—one that facilitates meaningful interoperability between all DIDs—then it will be worth it. I encourage you to DID:X as such a method: what can did:web, did:key, and many other DID methods look like under the DID:X umbrella?
Introducing DID:X
Imagining Sidetree V2, tentatively called DID:X–a placeholder name–we must improve on the solid foundation Sidetree v1 has set, learn from other successful identification systems, and achieve the principles set out earlier. We will address the shortcomings of Sidetree v1 and DIDs as a whole.
After speaking with implementers and community members and doing my own thinking–in no particular order–here's some of what I believe can be improved upon:
Simplification. It would be unfair to criticize KERI for its complexity but not Sidetree. I believe Sidetree is more human-friendly, though it's still extremely complex. I've spent almost three months trying to understand and implement Sidetree and still run into technical snags—the spec is dense and incomplete, as you often have to rely on implementations to fill in some crucial details like those around chain-specific parameters. Complexity is the root of all evil in software, especially for potentially world-impacting systems.
Firmer stance on cross-anchor interop. Sidetree today tries to have its cake and eat it too. This, in practice, has created divergence. To my knowledge, there's been no demonstrated interoperability between Sidetree methods, or even within them. This means that we must add well-specified anchor service parameters, enabling more implementations with compatibility out of the box. Sidetree must be a great unifier, mandating interop between methods, specifying exactly how this works, and making it dead simple to add support for new anchoring systems. I also believe allowing a flexible CAS is a mistake. IPFS is sufficient and will increase availability and resilience for all methods. This brings us to....
A single DID method that supports multiple anchoring services in a modular manner. The single DID method mandates a baseline of functionality such as key and signature types, DID operations, and required DID Document fields. DIDs are single-anchor, identified by an OP code in their identifier.
A flexible feature set. An expanded feature set around key operations. Support multisig DIDs. Sharded recovery using a scheme such as Shamir Secret Sharing. Have the ability to leverage chain-specific functionality for extension points, such as making use of Ethereum smart contracts for more complex operations. None of these options are required, but capabilities some implementations may choose to leverage. Of course, this creates a tradeoff with interoperability.
Cost reduction. From my experiments, running a conservatively specced ION node costs ~$500 a month on AWS. Too much for the average developer. Improvements can be made around data pruning and implementation efficiencies to lower compute, bandwidth, and storage costs. Implementing prunable state, simplifying file structures, and looking at using tools like JSON Patch, Automerge, or CBOR can all help here.
Late publish solutions. I've heard from several users and prospective users of Sidetree that late publish risk scares them. Essentially, late publishing introduces the risk that at any point in time, an unresolvable sidetree transaction can become resolvable and invalidate the current state of a DID. It is impossible to detect if any specific DID is at risk of a late publish attack and has an unresolvable state because the data stored on an anchor service does not identify which DIDs are associated with that transaction. Doing so would make many ledger solutions untenable. There are several potential mitigations to late publishing; at least one should be codified in the spec such as specifying a commitment scheme by which a DID-holder generates a cryptographic commitment over their current DID state, which can be used to accuse them should they attempt a late publish attack.
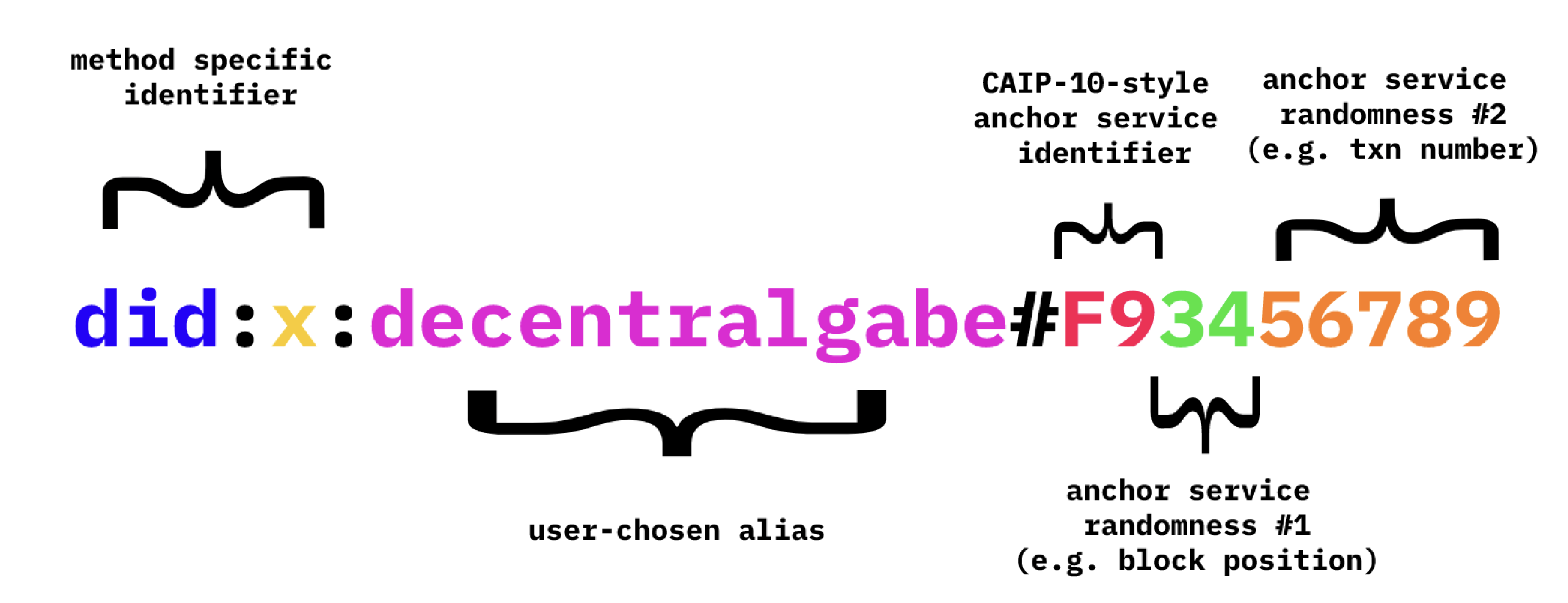
Human-friendly identifiers such as did:x:decentralgabe#F93456789 using a scheme such as the one identified in the following image:
Meaningful Adoption. Lastly, and possibly most importantly, DID:X needs to well supported, well tested, and broadly addopted. We need to improve test vectors and add a conformance suite which all implementations must comply with and pass to be noted as a sanctioned representation. We need committed implementers within and across anchor service implementations. I, with TBD's backing, will commit to one of the first open source implementations.
Now What?
I hope you have, at the least, had your interest piqued for the future of Sidetree. Together, I believe we can create an interoperable-first DID method that elevates the entire DID-ecosystem and decentralized web.
Ambitiously, I hope to get a draft of Sidetree V2 out by summer 2023. To do that, I need your help. The first step is gathering a feature list (let's start with what's above) with consensus and determining where the work will occur. I have heard rumblings that there's interest in moving the work to IETF. This is not something I'm opposed to. Wherever the work can get the broadest community support, it should be. In the meantime, we have rebooted the Sidetree Working Group at the DIF, which meets every Tuesday at 10 AM PST.
As a next step, I've created a survey you can fill out anonymously to help state your interests and preferences and share your feedback. If you are not using Sidetree today, I want to know why. If the vision for DID:X is not compelling to you, I want to know why. If you do not believe that DID:X will be the obvious next choice for anyone asking themselves, "what DID method should I use?" I want to know why.
Survey
Please take the survey and share it with your friends. I'll leave it open for about a month. If you'd like to see anything adjusted, reach out to me.